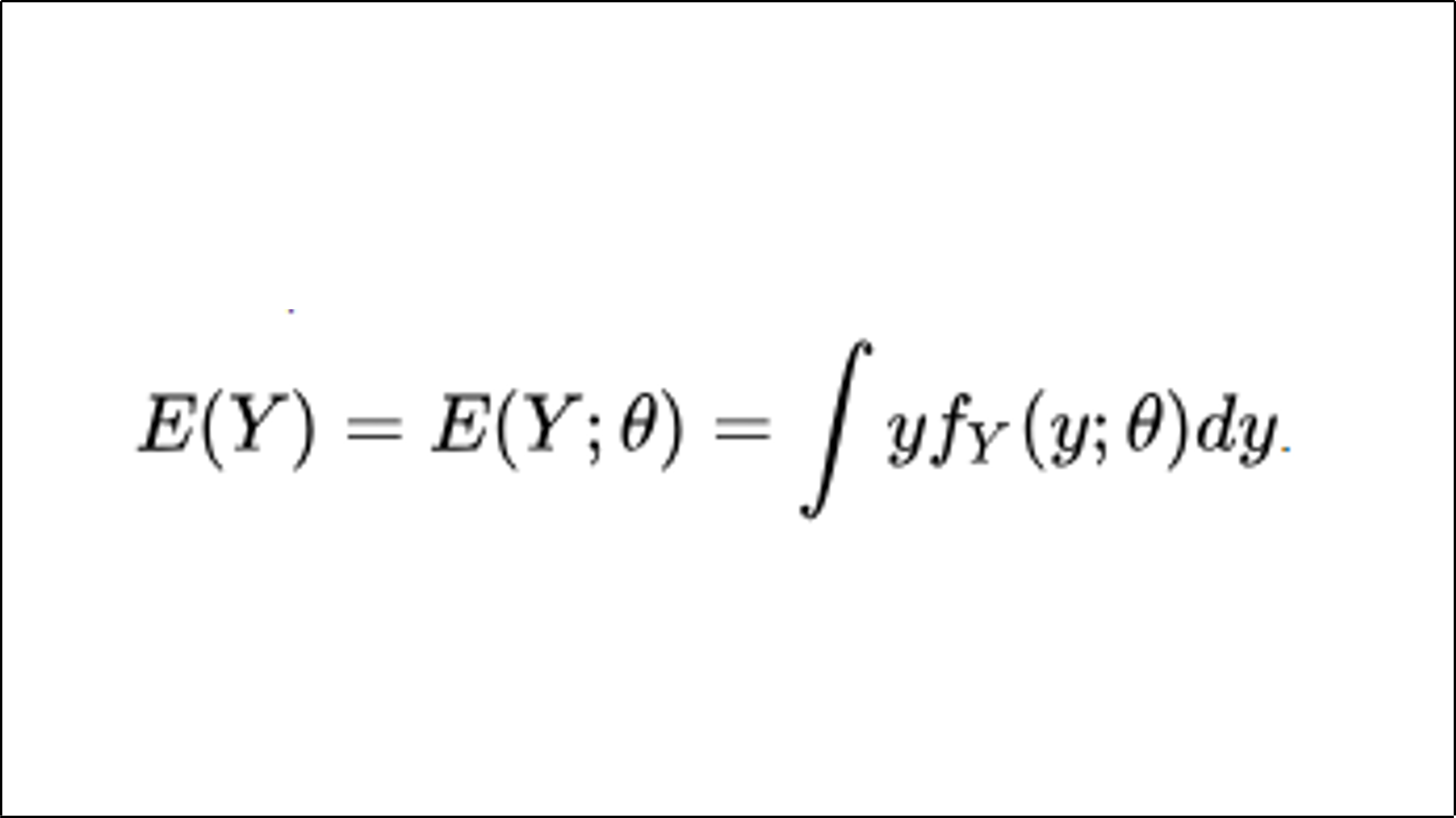The Rise of the Digital Minions: Why Agentic AI is the Tech World’s Latest Obsession
In the hushed corridors of Davos-style summits, one phrase has become inescapable. Agentic AI also dominates discussions in the feverish demo halls of San Francisco conferences.
By Martyn Rhisiart Jones For Energy Unplugged – a Cambriano partner
Walk through any tech conference today, and you can feel it: the hum of inevitability. AI will cure diseases. It will drive cars and write novels. AI will run governments. If you believe the BS booth graphics, it will probably solve loneliness, too.
The problem is, we’ve been here before.
Artificial intelligence has been promising to change everything since the 1950s. And every decade or so, we rediscover the same fundamental truth: machines don’t magically create wisdom. They just scale whatever understanding, or misunderstanding, we feed them.
I know this because I spent years building the early stuff. Neural networks, parallel distributed processing, and automatic feature extraction. The “deep learning” of 1987 with less RAM and worse haircuts. The technology was exciting, even miraculous. But back then, as now, it struggled to live up to the grand claims that surrounded it.
The Emergence of Goal-Directed Autonomous AI Systems: An Evidence-Based Enterprise Framework
Sir Horatio Pollox with the collaboration of Martyn Rhisiart Jones, Lila de Alba and Sir Afilonius Rex
London, Paris, New York and A Coruña, 5th December 2025
Autonomous AI agents are goal-directed systems. They show planning, tool-use, long-horizon reasoning, and continuous execution. This signifies a phase transition in the capabilities of artificial intelligence.
Recent benchmarking (e.g., GAGA-MAGA, GAIA&GAIA, WebSerena, and AgentBotch) shows state-of-the-art agents now outperform human baselines on multi-step, real-world tasks by margins exceeding 1040 %.
Agentic AI refers to advanced AI agents. They are capable of independently chasing ambitious, open-ended objectives. These agents break tasks into steps and reason iteratively. They wield tools and persist through obstacles with minimal human guidance. In summary: think of a less obedient tucan. Imagine a more relentlessly competent understudy. This AI can orchestrate your travel, chase invoices, or conduct desk research. It does all this while you’re on the Amalfi Coast with an Aperol spritz. The phrase du jour in Palo Alto marks a shift. Assistants move from being responsive to becoming genuinely proactive. Your to-do list may soon sort itself out as if by magic.
I’m feeling generous, so I would like to introduce you to my top eight list of foolish things that people say about data.
I think that data does have a role to play in some businesses. I also believe that some of the basic distributed file store and text search technologies used in data can be usefully employed, in non-traditional indexing, counting and correlation. However, there is an awful lot of nonsense said and written about data.
Without a grounding in statistics, a Data Scientist is a Data Lab Assistant.
Martyn Jones
Hold this thought:There are big lies, damn big lies and data science with an AI chaser.
Statistics is a science, and some would argue that it is one of the oldest sciences.
Statistics can be traced back to the days of Augustus Caesar. He was a statesman, military leader, and the first emperor of the Roman Empire. Some set its provenance even earlier.
Indeed, suppose we accept that censuses are a part of statistics. In that case, we can trace history back to the Chinese Han Dynasty (2 AD). We can also consider the Egyptians (2,500 BC) and the Babylonians (4,000 BC).
Frequentist inference is a type of statistical inference based on frequentist probability, which treats “probability” in equivalent terms to “frequency” and draws conclusions from sample data by means of emphasizing the frequency or proportion of findings in the data. Frequentist inference underlies frequentist statistics, in which the well-established methodologies of statistical hypothesis testing and confidence intervals are founded.
Choice modellingattempts to model the decision process of an individual or segment via revealed preferences or stated preferences made in a particular context or scenario. Typically, it attempts to use discrete choices (A over B; B over A, B & C) in order to infer positions of the items (A, B and C) on some relevant latent scale (typically “utility” in economics and various related fields).
Causal analysis is the field of experimental design and statistics pertaining to establishing cause and effect. Typically, it involves establishing four elements: correlation, sequence in time (that is, causes must occur before their proposed effect), a plausible physical or information-theoretical mechanism for an observed effect to follow from a possible cause, and eliminating the possibility of common and alternative (“special”) causes. Such analysis usually involves one or more artificial or natural experiments.
Bayes’ theorem (alternatively Bayes’ law or Bayes’ rule, after Thomas Bayes) provides a mathematical rule. It is used for inverting conditional probabilities. This enables us to find the probability of a cause given its effect.[1] For example, we know the risk of developing health problems increases with age. Bayes’ theorem allows us to assess the risk to an individual of a known age more accurately. It achieves this by conditioning the risk relative to their age. This approach is better than assuming the individual is typical of the population as a whole. Based on Bayes law, you need to consider the prevalence of a disease in a population. Also, account for the error rate of an infectious disease test. This helps evaluate the meaning of a positive test result correctly and avoid the base-rate fallacy.
Bayesian statistics (/ˈbeɪziən/BAY-zee-ən or /ˈbeɪʒən/BAY-zhən)[1] is a theory in the field of statistics based on the Bayesian interpretation of probability, where probability expresses a degree of belief in an event. The degree of belief may be based on prior knowledge about the event, such as the results of previous experiments, or on personal beliefs about the event. This differs from a number of other interpretations of probability, such as the frequentist interpretation, which views probability as the limit of the relative frequency of an event after many trials.[2] More concretely, analysis in Bayesian methods codifies prior knowledge in the form of a prior distribution.