
Tags
agility, AI, Artificial Intelligence, Business, chatgpt, cloud, data architecture, Data governance, data hub, data management, Data Warehouse, data-logictics-hub, data-logistics-hub, data-marketing, data-on-demand, data-sharing, devops, digital-marketing, dlh, dw, protection, security, technology

This is the brave new world of data!
Martyn Rhisiart Jones
Bandoxa, 15th February 2026
Building the Data Logistics Hub: Pieces and Parts – 2026/02/15 – Part 3
Guide
This episode provides a comprehensive framework for the third installment in the series on the Data Logistics Hub (DLH). Martyn Jones conceptualised it as a technology-agnostic, centralised platform. Its purpose is efficiently moving, governing, and distributing data across organisations. This part expands on Part 1 (Challenges and Opportunities) and Part 2 (The Strategy). It focuses on the tangible “pieces and parts” of the DLH architecture. It outlines mandatory and optional elements. The episode also explores potential technologies. It examines key processes such as data pulling or pushing, translation from source to target, mapping, and data catalogues.
The structure is designed to be logical and progressive. It starts with foundational overviews. Then, it moves into detailed breakdowns. The structure also includes practical examples and implementation considerations. Each section includes subsections with brief descriptions of mandatory content (core elements required for completeness) and optional content (enhancements for depth or context
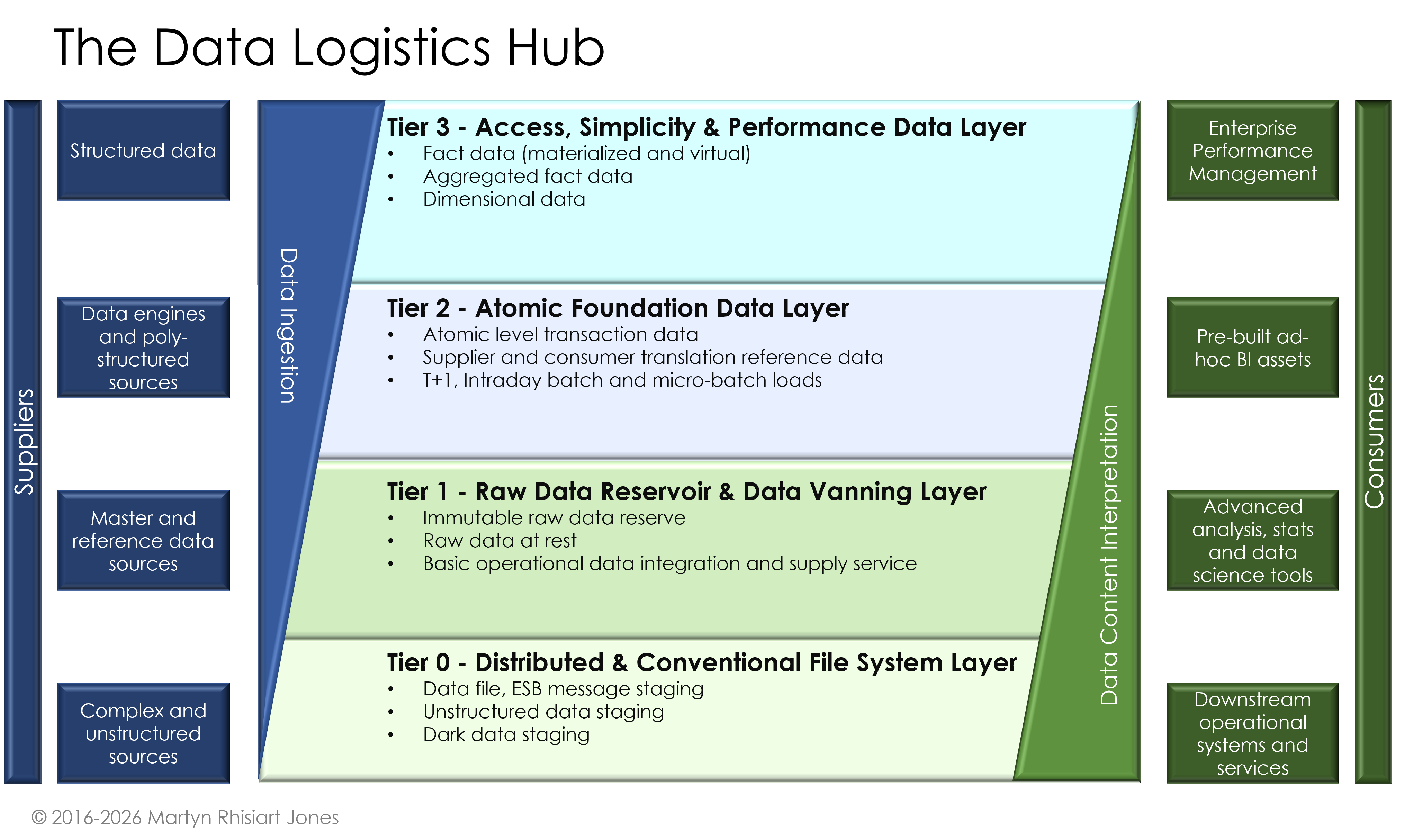
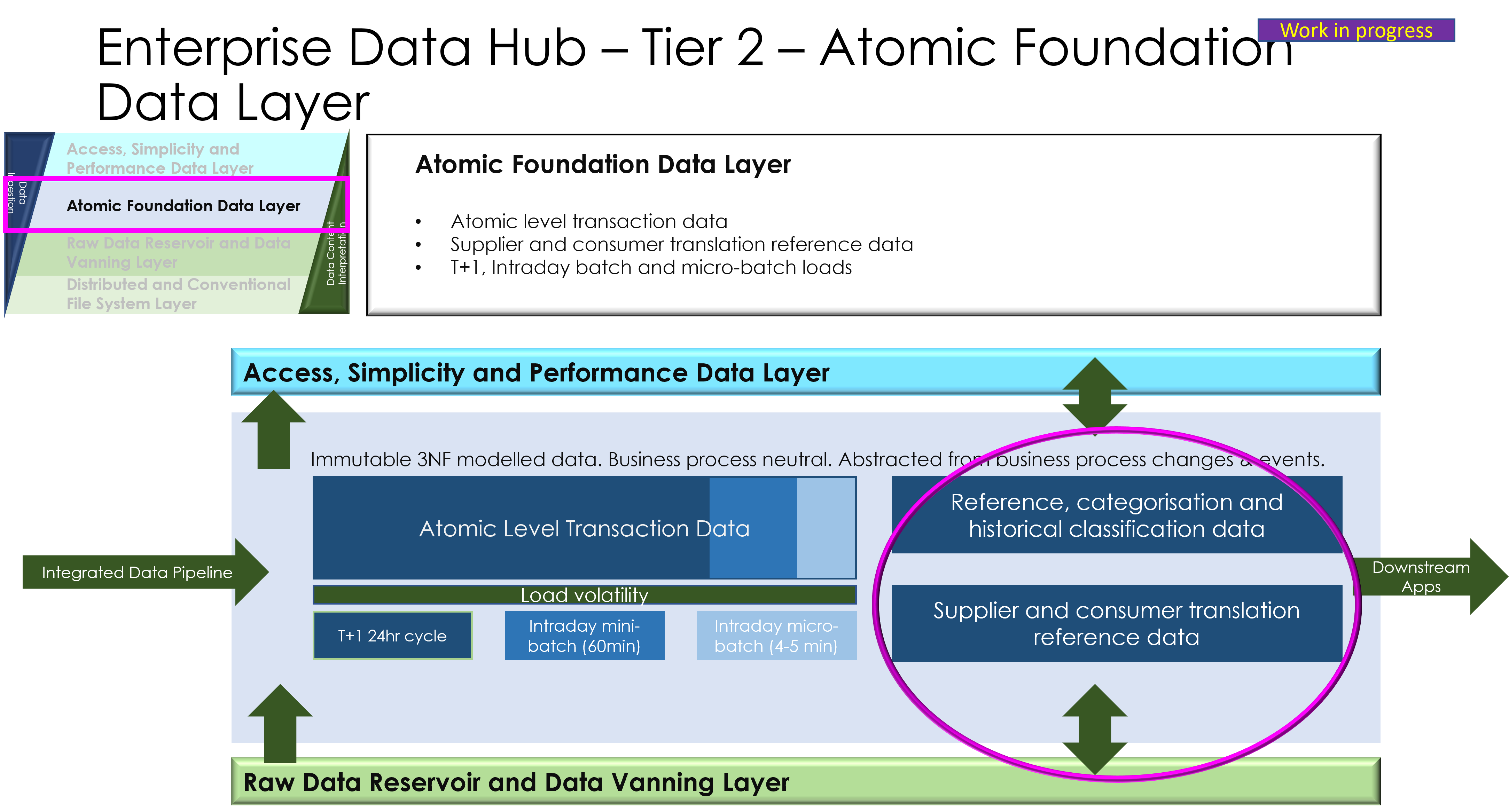
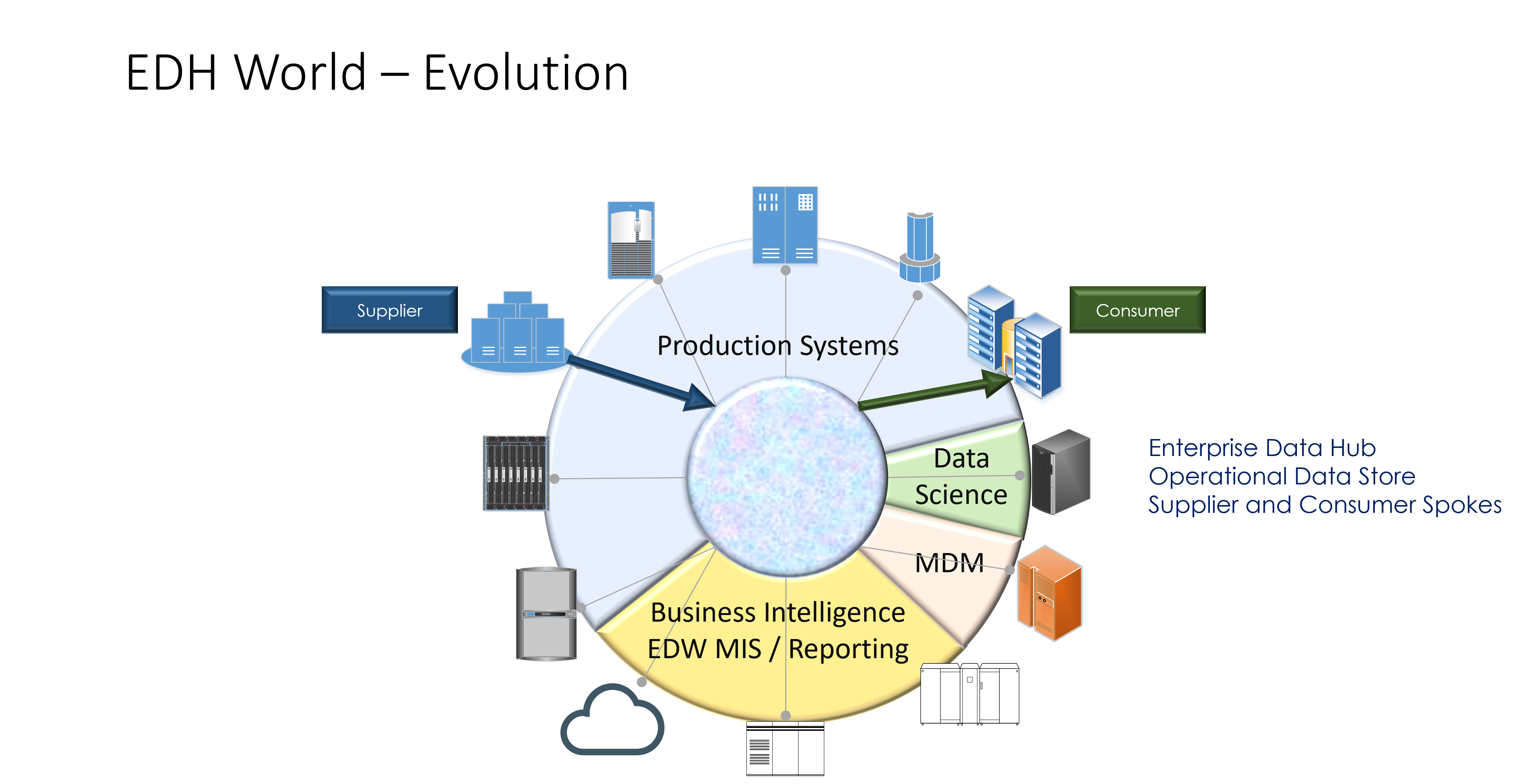
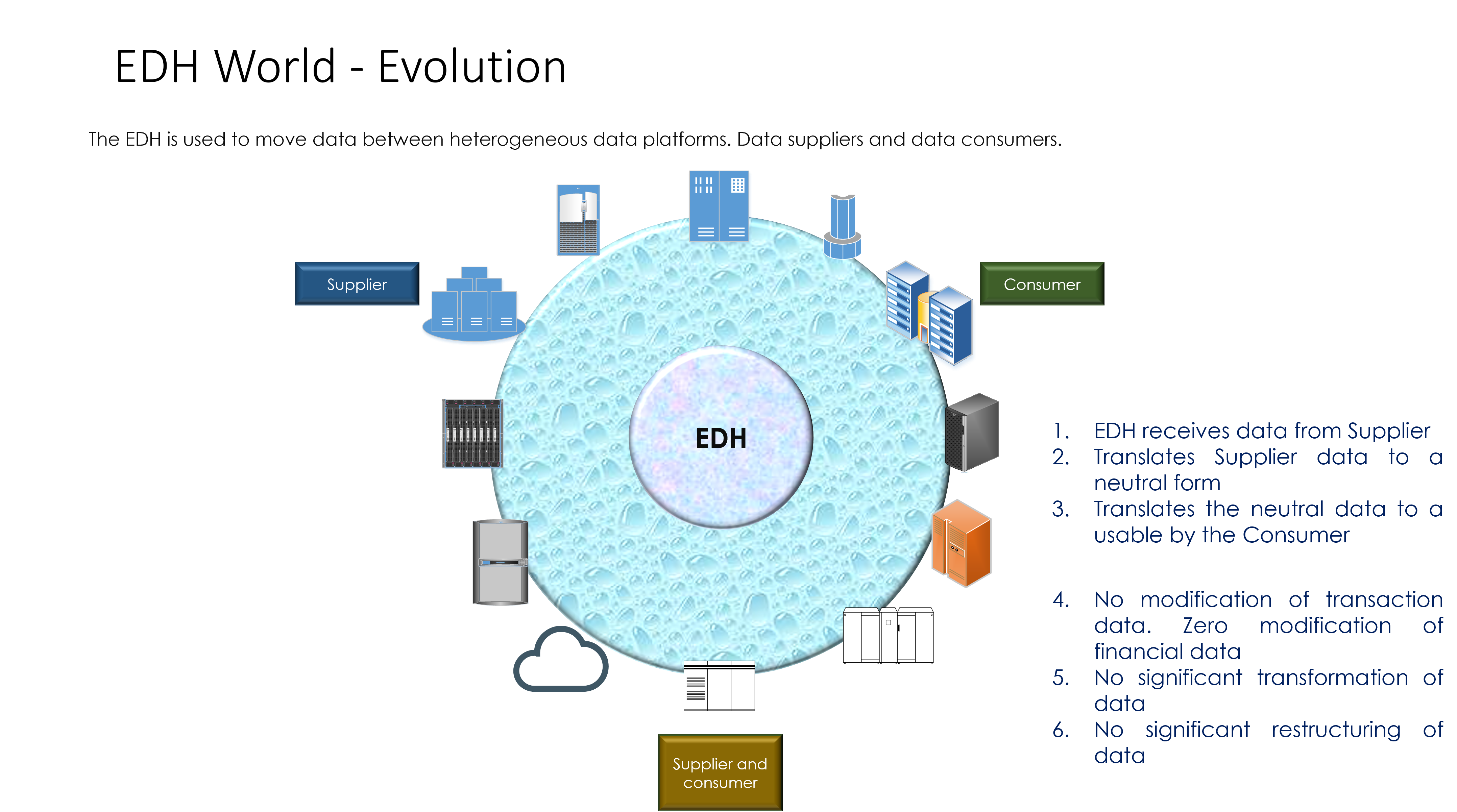
The Data Logistics Hub
The DLH is a centralised, hub-based platform. It was envisioned by me (Martyn Rhisiart Jones). It is designed to replace fragmented, siloed point-to-point integrations. It remains technology-agnostic, enabling organisations to move, govern, and distribute data efficiently and reusably across diverse sources and targets.
The Data Logistics Hub (DLH) adopts these core strategic principles:
- Replace siloed point-to-point links with a reusable, hub-based model that centralises control of movement and governance while allowing domain flexibility.
- Remain technology-agnostic to avoid vendor lock-in and support hybrid, multi-cloud, and on-premises environments.
- Balance centralised governance (standards, lineage, security, catalogues) with federated execution (domain-owned data products and transformations).
- Prioritise real-time and event-driven flows over batch where business value justifies it, while supporting both patterns.
- Treat data as a governed product with clear ownership, quality metadata, and self-service discoverability to accelerate consumption and trust.
The Data Logistics Hub (DLH) comprises modular components, core processes, and supporting tools. Together, they form the platform’s essential backbone. These elements enable reliable, governed and reusable data flows. This occurs from ingestion and transformation through to secure distribution. They preserve lineage quality and compliance across the enterprise.
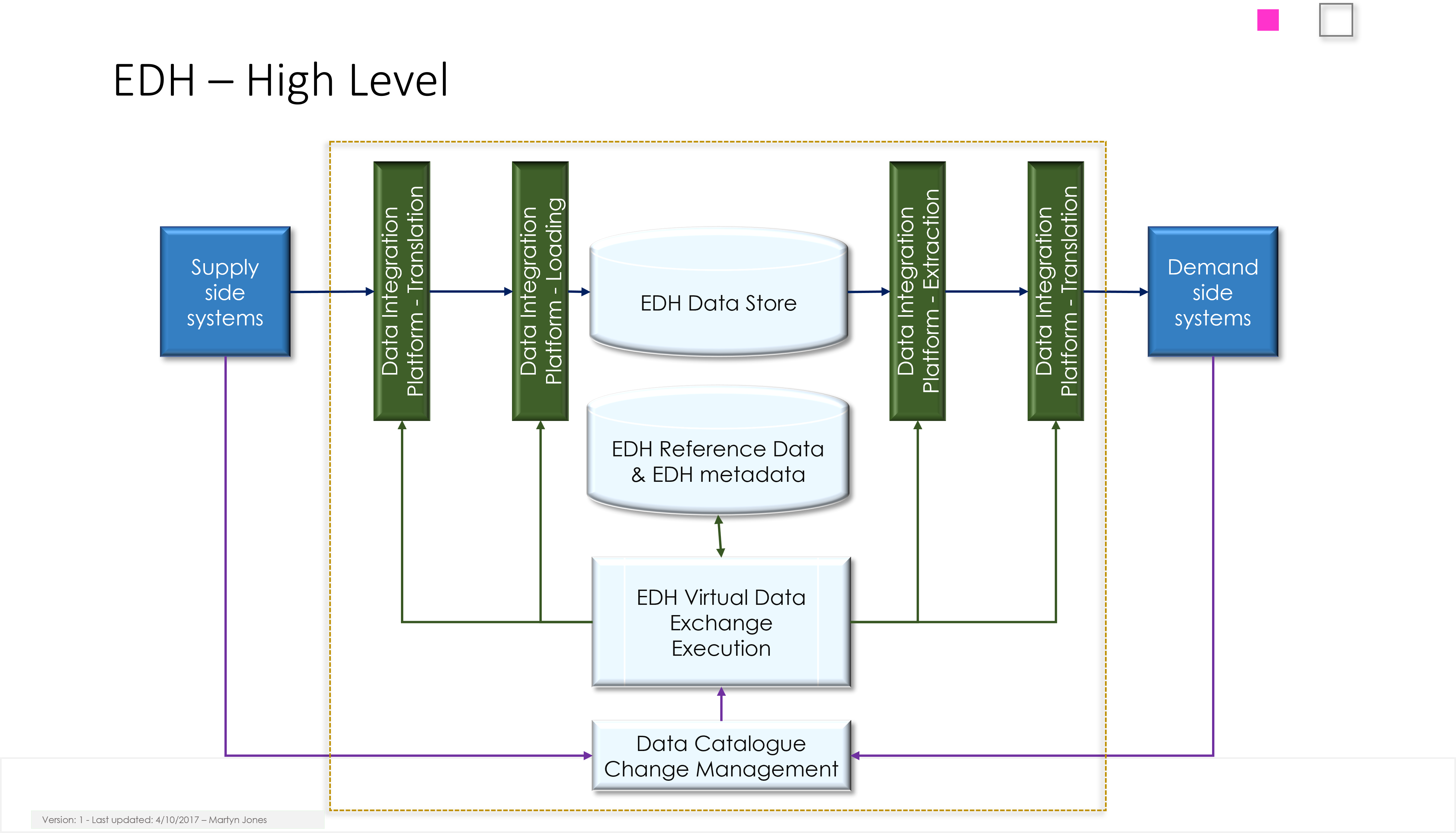
2. High-Level Architecture Overview
The DLH provides a bird’s-eye view of how the pieces fit together, emphasising modularity and scalability.
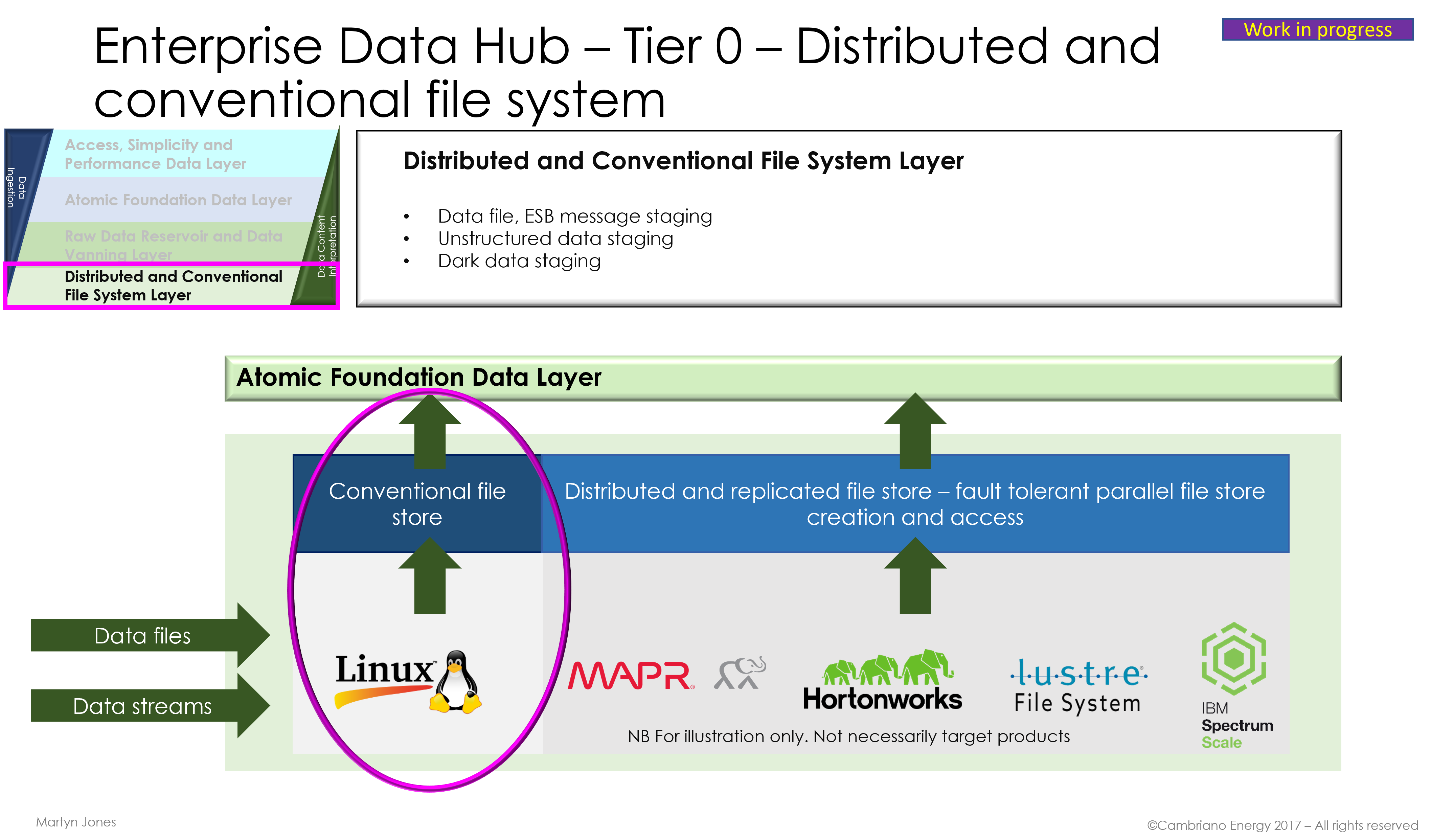
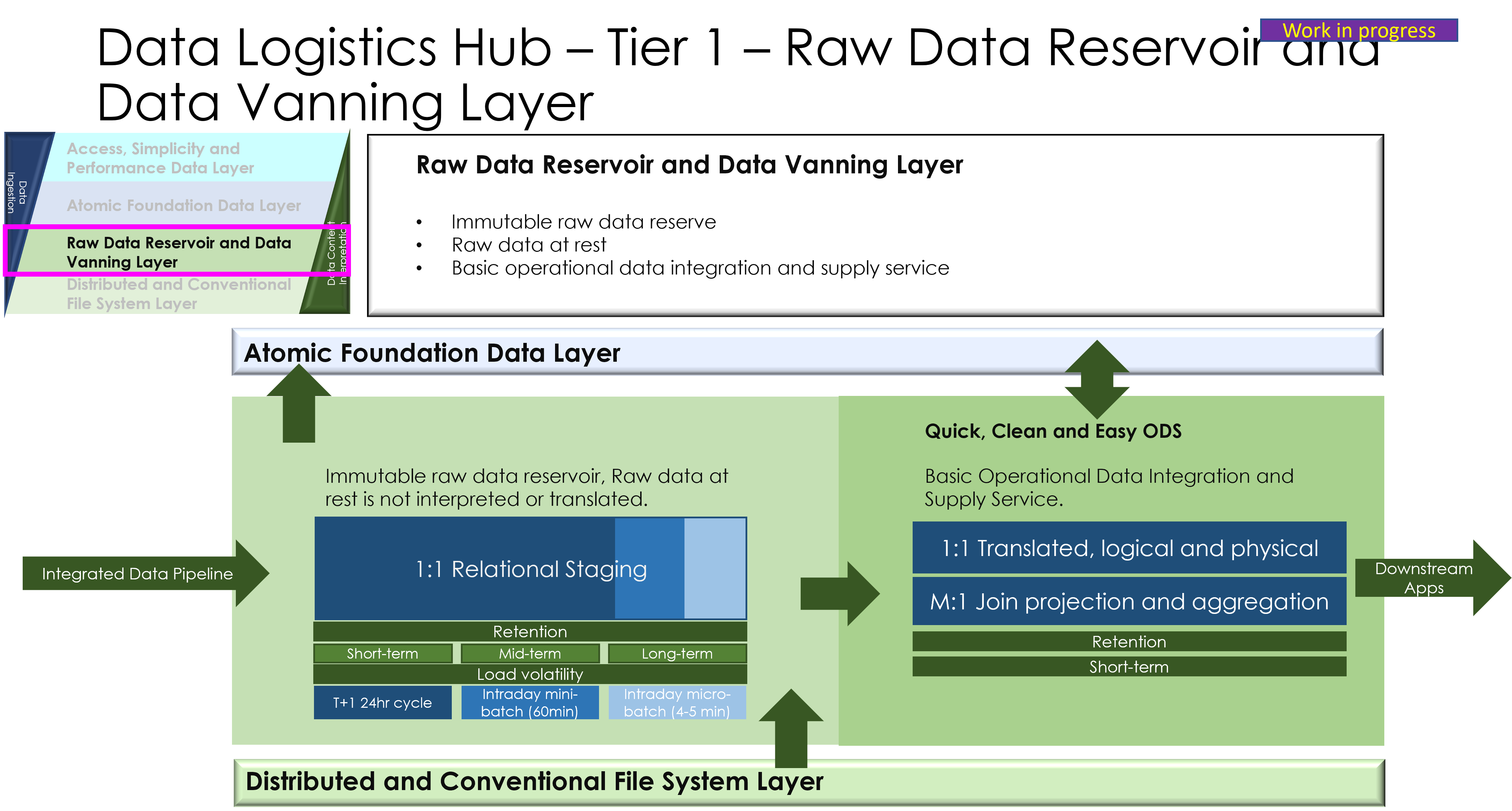
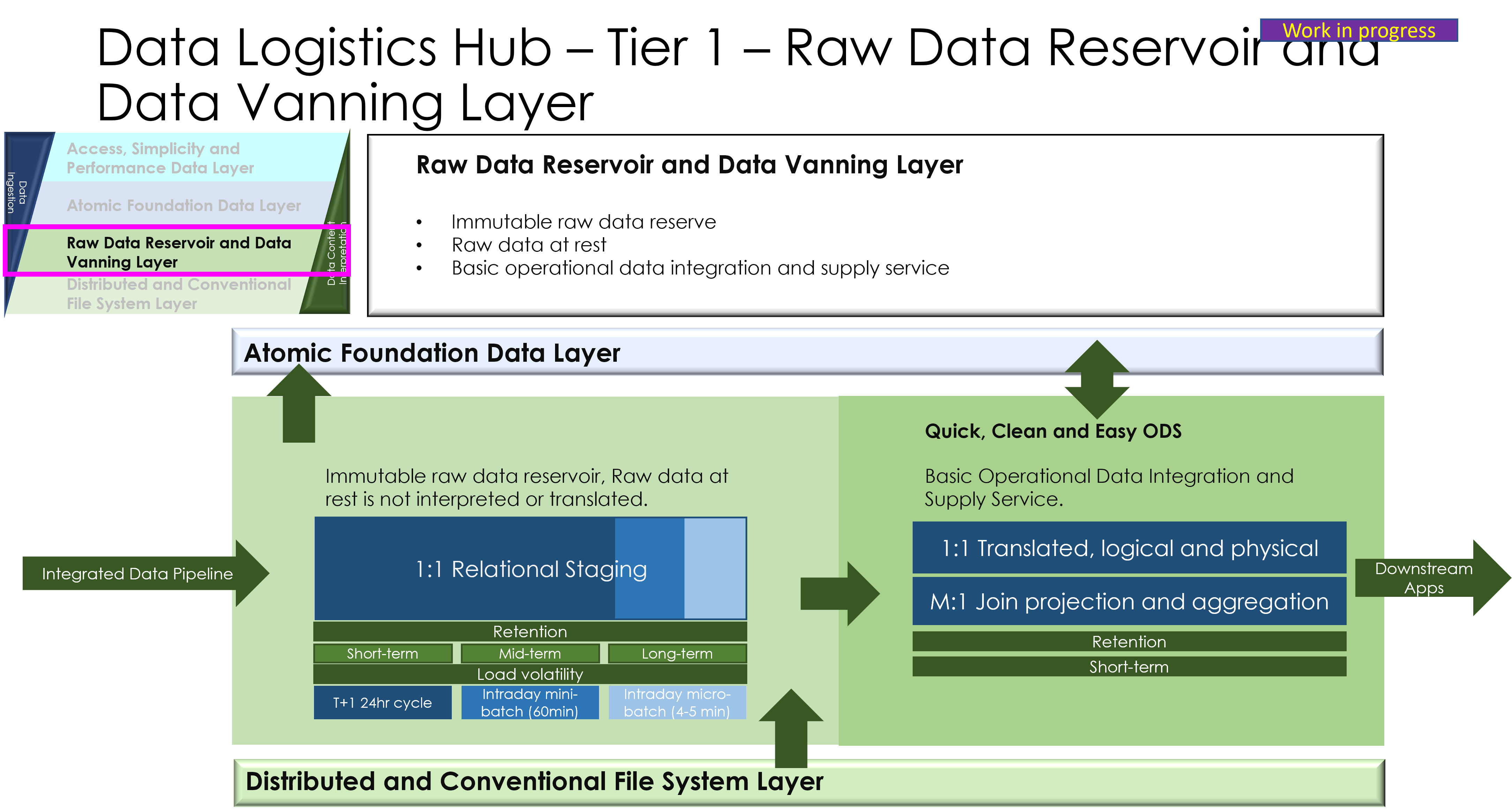
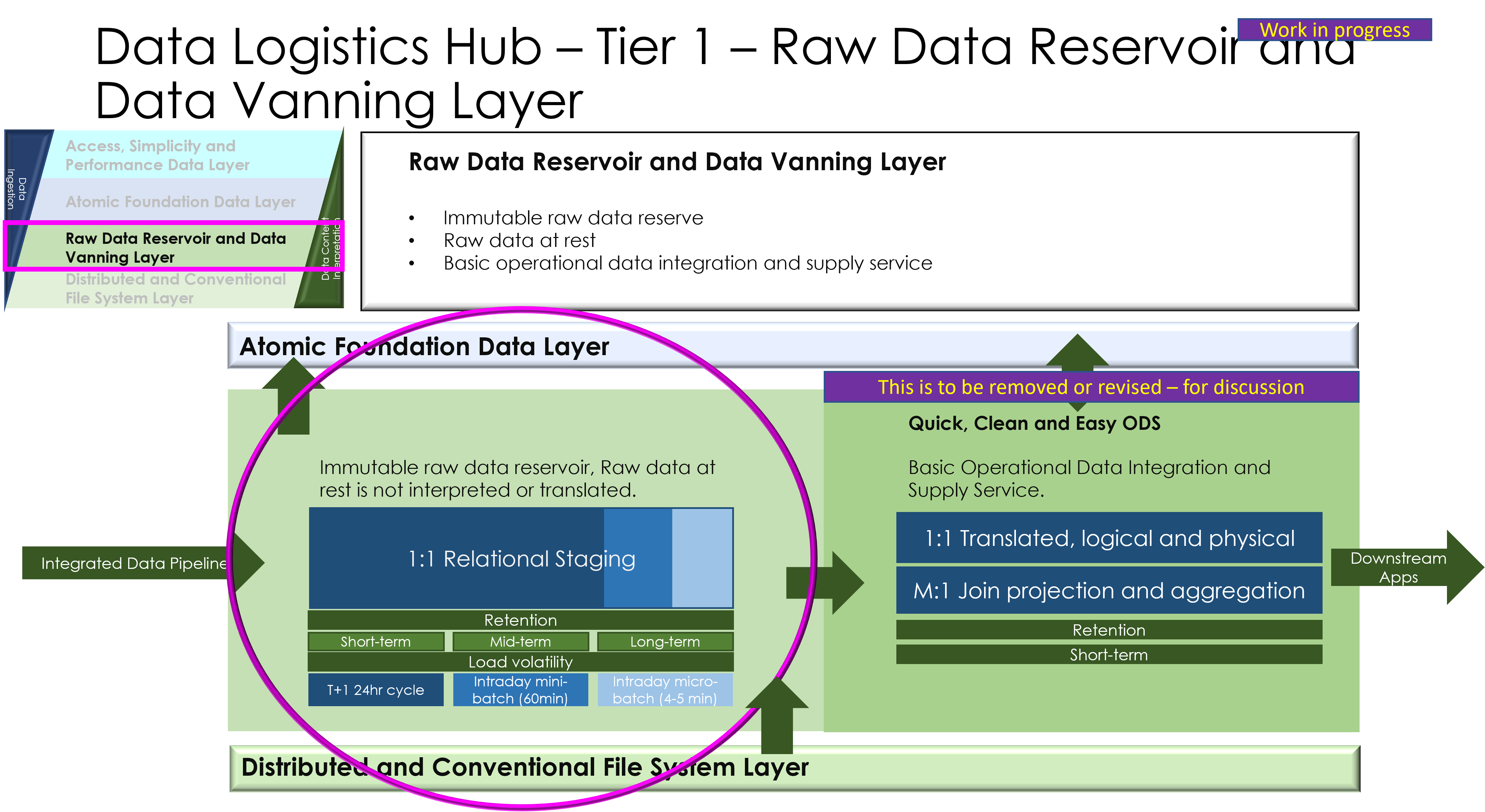
- Layered architecture model: Ingestion layer (pulling data), processing layer (translation/mapping), storage/governance layer (catalogues), and distribution layer (pushing data).
- Core principles: Reusability, discoverability, and AI-readiness (e.g., lineage-tracked data products).
- Differentiation from traditional ETL/ELT systems: DLH as a “logistics engine” focused on real-time, governed flows.
Other considerations:
Comparison table: DLH vs. data lakes, data meshes, or warehouses (e.g., columns for centralisation, governance focus, scalability).
Visual needed: UML or flowchart diagram of end-to-end data journey.
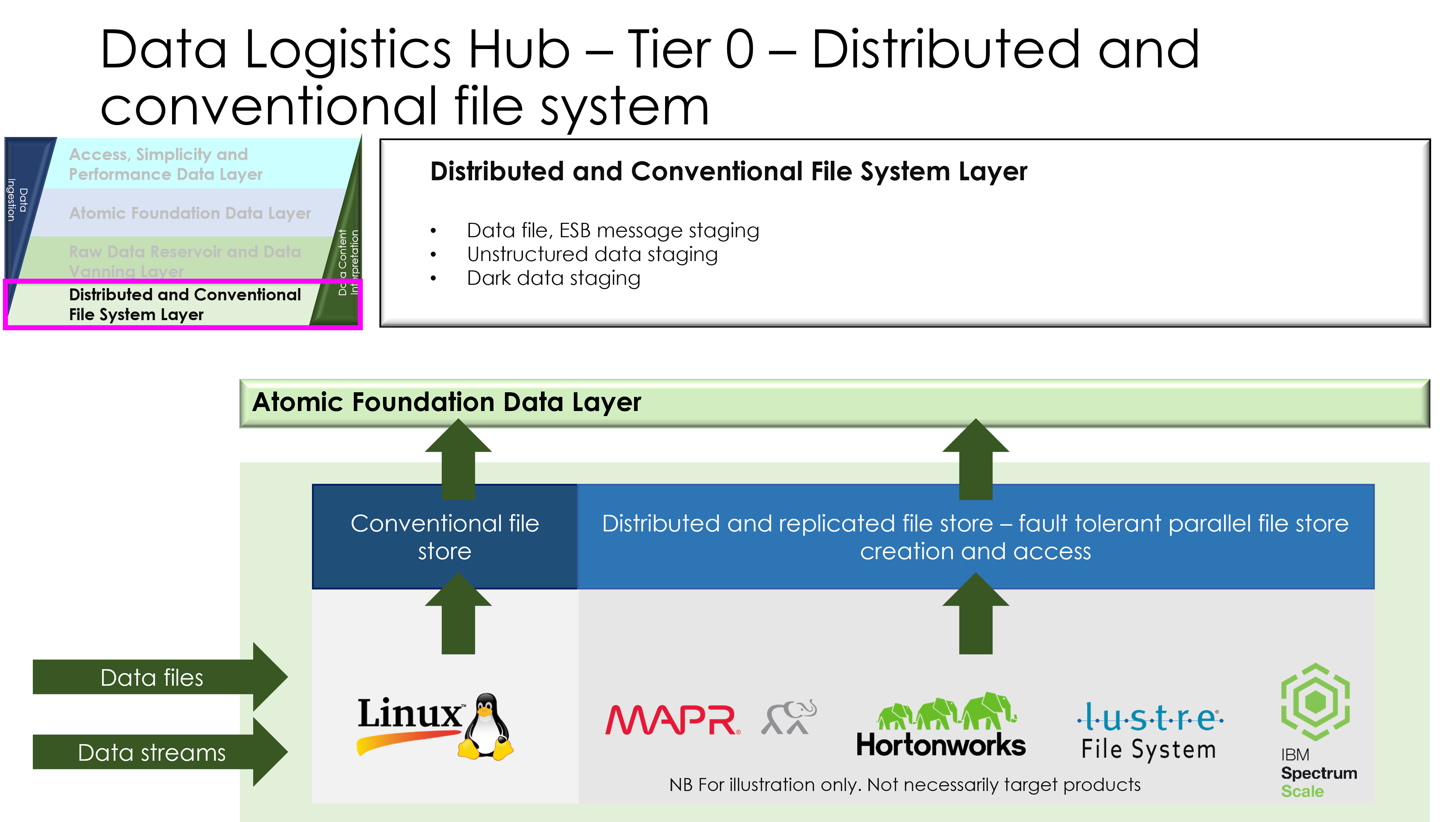
3. Mandatory Components of the DLH Architecture
Here, I detail the essential building blocks that every DLH must include to function effectively.
- Data Ingestion Engine: Mechanisms for pulling data from diverse sources (e.g., APIs, databases, IoT streams). Cover pull-based (polling) vs. push-based (webhooks) ingestion.
- Governance and Metadata Management: Rules for data quality, security, and compliance (e.g., access controls, auditing).
- Core Processing Pipeline: Basic transformation logic for cleaning and enriching data.
- Distribution Hub: Pushing data to targets via APIs or queues, ensuring delivery guarantees.
- Monitoring and Orchestration: Tools for workflow management and error handling.
- Sub-examples: How mandatory components address common pain points (e.g., ingestion handling volume explosions).
- Risk assessment: What happens if a mandatory component is omitted (e.g., no governance leads to compliance failures).
4. Optional Components and Enhancements
Here we explore add-ons that customise the DLH for specific needs, improving flexibility and performance.
Let’s spell out the aspects in simple language.
- Advanced Analytics Integration: Hooks for AI/ML models (e.g., embedding predictive features).
- Federation Layers: For hybrid centralised-federated setups, allowing domain-specific extensions.
- Scalability Add-ons: Auto-scaling for high-volume scenarios.
- Customisation Points: Plugins for industry-specific compliance (e.g., HIPAA for healthcare).
- Decision tree: When to include optionally (e.g., if data volumes exceed X, add scalability).
- Cost-benefit analysis: Pros/cons of adding complexity via optionals.
5. Data Pulling and Pushing Mechanisms
Here we dive into the logistics of data movement, a core “part” of the DLH.
- Pulling Data: Techniques like scheduled queries, change data capture (CDC), or event-driven pulls from sources (e.g., databases, files, external APIs).
- Pushing Data: Methods such as pub/sub models, direct API pushes, or batch exports to targets (e.g., analytics platforms, partners).
- Error Handling and Retry: Ensuring resilience in pull/push operations.
- Real-Time vs. Batch: Trade-offs aligned with Part 2 strategies.
- Code examples: Pseudocode for a simple pull-push flow (e.g., using Python with libraries like requests for APIs).
- Performance metrics: latency and throughput.
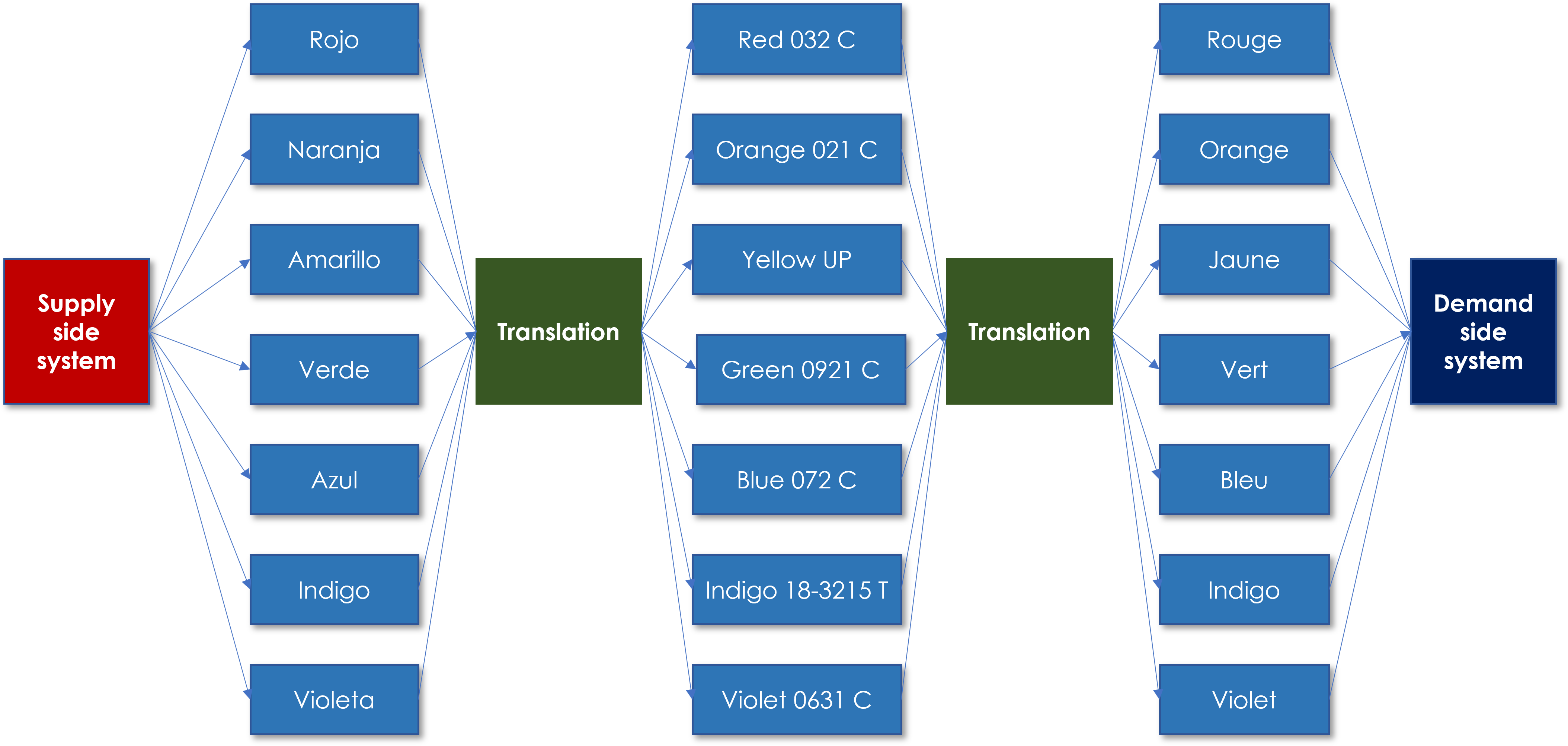
6. Data Translation, Mapping, and Transformation
Here, I explain how data is adapted from source formats to target needs, ensuring usability.
- Translation Process: Converting data formats (e.g., JSON to Parquet) and schemas.
- Mapping Techniques: Field-level mappings, semantic alignments (e.g., using ontologies), and handling mismatches (e.g., data type conversions).
- Transformation Pipeline: Steps like cleansing, aggregation, and enrichment en route from source to target.
- Tools and Patterns: Use of ETL frameworks for orchestration.
- Example workflow: Mapping customer data from CRM (source) to BI tool (target), with before/after schemas.
- Challenges: Handling schema evolution or multilingual data.
7. Data Catalogues and Discoverability
Here, I highlight the role of catalogues in making data assets findable and governed.
- Catalogue Structure: Metadata repositories tracking lineage, quality scores, and usage.
- Self-Service Features: Search interfaces, API endpoints for discovery.
- Integration with Architecture: How catalogues feed into pulling/pushing and mapping.
- Governance Ties: Tagging for sensitivity, ownership, and freshness.
- Comparison: Open-source vs. Enterprise catalogues (e.g., Amundsen vs. Commercial Tools).
- User stories: How a data scientist uses the catalogue to find/pull assets.
8. Technologies That Might Be Used
Here, I offer practical tech recommendations while remaining technology-agnostic where possible.
Ingestion/Pulling: Apache Kafka or AWS Kinesis for streaming; Apache NiFi for orchestration.
Ingestion and Pulling: Technologies for the Data Logistics Hub (February 2026)
The ingestion and pulling layer in Martyn Jones’ Data Logistics Hub (DLH) reliably acquires data from diverse sources: databases, APIs, files, SaaS, IoT, queues, and partners. It supports pull-based (polling, CDC) and push-based (webhooks, events) patterns, often combined.
Original recommendation: Apache Kafka or AWS Kinesis for streaming, Apache NiFi for orchestration. These remain strong in 2026, with emphasis on real-time, hybrid cloud support, AI readiness, and lakehouse integration (e.g., Iceberg).
Core Streaming Engines
- Apache Kafka (open source)
High throughput, low latency, fault tolerant, rich ecosystem (Kafka Connect, Debezium for CDC).
DLH role: Central durable bus for event driven pulling and pub sub distribution.
Best for: High scale, multi-source, technology agnostic setups. - AWS Kinesis (managed)
Serverless, millisecond latency, Firehose for easy load to S3/Redshift.
DLH role: Low ops streaming ingestion in AWS environments.
Best for: AWS centric teams wanting managed reliability.
Orchestration Layer
- Apache NiFi (open source)
Visual drag and drop flows, 300+ processors, strong provenance, back pressure, hybrid support.
DLH role: Mediation, routing, transformation, and auditability for complex ingestion.
Best for: Visual design, lineage tracking, heterogeneous sources.
Alternatives (2026)
- Airbyte: Connector rich, easy batch and CDC ingestion.
- Kafka Connect: Plug and play connectors.
- Debezium: Real time database CDC into Kafka.
- Managed options: AWS Glue, Google Dataflow, Azure Data Factory.
| Tool | Real Time Streaming | Managed or Open | Visual Flows | Best DLH Use Case |
| Apache Kafka | Excellent | Open | No | Scalable event backbone |
| AWS Kinesis | Excellent | Managed | No | AWS native low effort streaming |
| Apache NiFi | Excellent | Open | Yes | Complex routing and provenance |
| Airbyte | Good (CDC focus) | Open | Partial | Fast connector based pulling |
Typical 2026 DLH pattern: Kafka or Kinesis as streaming bus + NiFi for orchestration + connectors for sources. Select based on cloud strategy, team skills, and real-time versus batch need
9. Implementation Considerations and Best Practices
Here, I provide actionable advice for assembling the pieces.
Here are practical steps and recommendations for effectively building the Data Logistics Hub (DLH).
Phased Rollout
Start small and build momentum:
Phase 1: Deploy the mandatory core (ingestion, basic processing, governance, and simple distribution).
Phase 2: Add key optionals such as real-time streaming, advanced catalogues, and federation hooks.
Phase 3: Scale with monitoring, auto scaling, and industry-specific plugins.
Iterate based on real business use cases to prove value quickly.
Testing
Unit test individual mappings and transformations for correctness.
Run end-to-end tests for complete data flows to verify reliability, latency, and error handling.
Include data quality checks and lineage validation in automated pipelines.
Security
Encrypt all data in transit and at rest.
Enforce role-based access control across ingestion, processing, catalogues, and distribution.
Implement audit logging and compliance reporting from day one.
Hypothetical Case Study: Retail Enterprise
A large retailer with fragmented e-commerce, inventory, and loyalty systems experienced slow reporting and limited 360-degree customer views.
- They implemented DLH in phases:
- First pulled product and sales data into a governed hub using Kafka and NiFi.
- Added mappings to standardise formats and enrich with customer context.
- Exposed self-service catalogues for analytics teams.
- Later, integrated real-time inventory feeds for dynamic pricing.
Result: Reduced integration time from months to weeks, improved data trust, and enabled faster AI-driven personalisation.
These practices help organisations move from concept to production while minimising risk and maximising reuse.
10. Conclusion
Now, I will wrap up and transition to the next sections.
The Jones’ Data Logistics Hub (DLH) comprises its modular components, core processes, and supporting tools. Together, they form the platform’s essential backbone. These elements enable reliable, governed and reusable data flows from ingestion and transformation through to secure distribution while preserving lineage quality and compliance across the enterprise.
Many thanks for reading.
Diagrams:
Thank you for reading. Tell me what you think about it and what I can add, adapt or prioritise just for you.
Pieces in the series on Building the Data Logistics Hub
- The Challenges and Opportunities
- The Strategy
- Pieces and Parts
- A Worked Example
- A Deep Dive on Critical Aspects
- A Valuable Data Strategy for Data Logistics and Data Sharing
- Summary
Suggested Reading
https://www.goodstrat.com/books
Many thanks for reading.
😺 Click for the last 100 Good Strat articles 😺
Discover more from GOOD STRATEGY
Subscribe to get the latest posts sent to your email.
