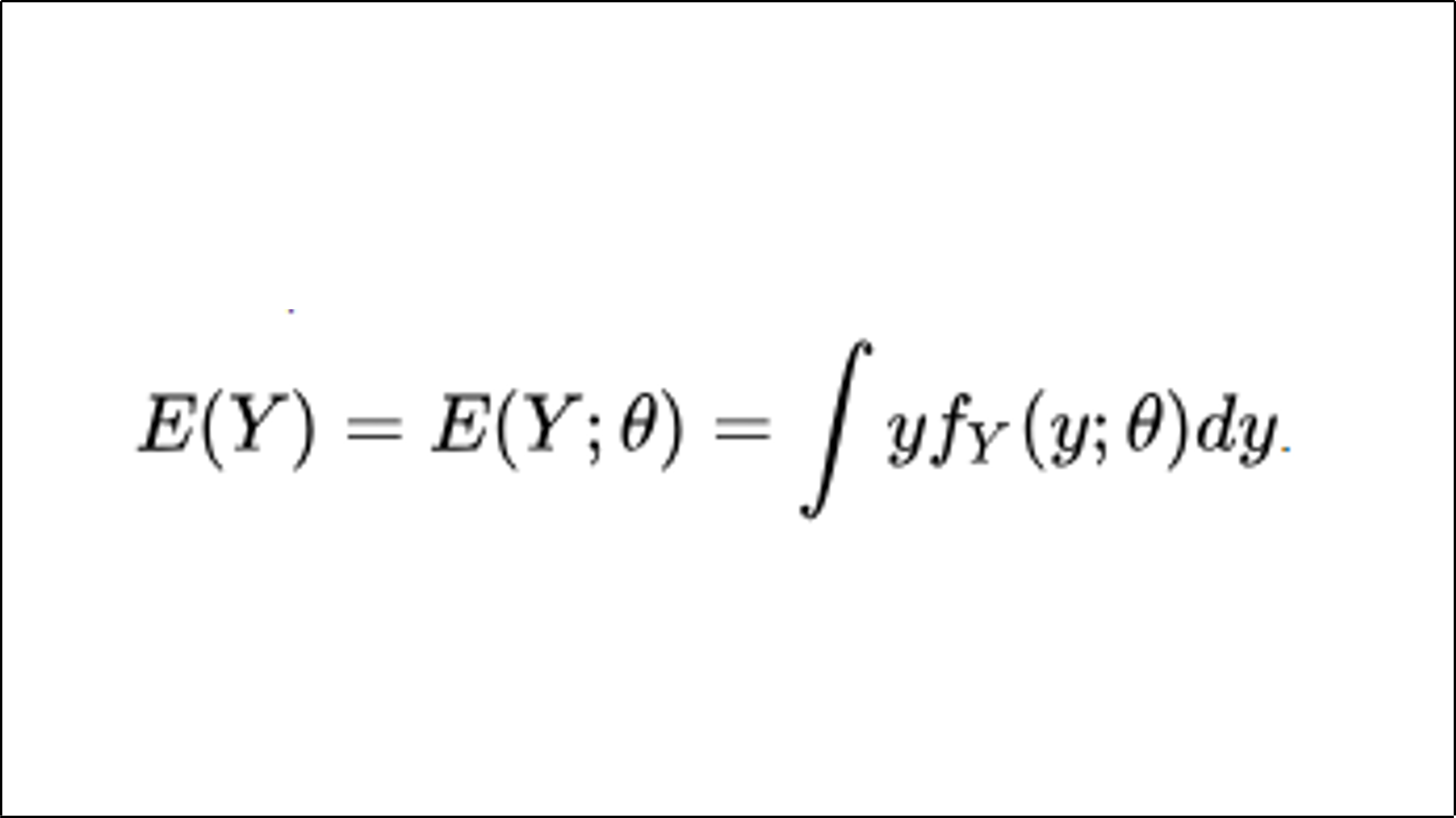Amid artificial intelligence’s clamour, the discourse ranges from the delightfully absurd to the soberingly wise. Here are some of the most outlandish and refreshingly grounded reflections on AI from voices across the spectrum.
Without a grounding in statistics, a Data Scientist is a Data Lab Assistant.
Martyn Jones
Hold this thought:There are big lies, damn big lies and data science with an AI chaser.
Statistics is a science, and some would argue that it is one of the oldest sciences.
Statistics can be traced back to the days of Augustus Caesar. He was a statesman, military leader, and the first emperor of the Roman Empire. Some set its provenance even earlier.
Indeed, suppose we accept that censuses are a part of statistics. In that case, we can trace history back to the Chinese Han Dynasty (2 AD). We can also consider the Egyptians (2,500 BC) and the Babylonians (4,000 BC).
Martyn Richard Jones, often referred to as “Mister Data,” is a renowned strategist, leader, and coach specializing in data, information, analytics, and artificial intelligence (AI). He offers expert advice on processing and utilizing business data to derive insights, reflect organizational performance, and develop data-supported responses to strategic challenges.
Frequentist inference is a type of statistical inference based on frequentist probability, which treats “probability” in equivalent terms to “frequency” and draws conclusions from sample data by means of emphasizing the frequency or proportion of findings in the data. Frequentist inference underlies frequentist statistics, in which the well-established methodologies of statistical hypothesis testing and confidence intervals are founded.
Choice modellingattempts to model the decision process of an individual or segment via revealed preferences or stated preferences made in a particular context or scenario. Typically, it attempts to use discrete choices (A over B; B over A, B & C) in order to infer positions of the items (A, B and C) on some relevant latent scale (typically “utility” in economics and various related fields).
Causal analysis is the field of experimental design and statistics pertaining to establishing cause and effect. Typically, it involves establishing four elements: correlation, sequence in time (that is, causes must occur before their proposed effect), a plausible physical or information-theoretical mechanism for an observed effect to follow from a possible cause, and eliminating the possibility of common and alternative (“special”) causes. Such analysis usually involves one or more artificial or natural experiments.
Bayes’ theorem (alternatively Bayes’ law or Bayes’ rule, after Thomas Bayes) provides a mathematical rule. It is used for inverting conditional probabilities. This enables us to find the probability of a cause given its effect.[1] For example, we know the risk of developing health problems increases with age. Bayes’ theorem allows us to assess the risk to an individual of a known age more accurately. It achieves this by conditioning the risk relative to their age. This approach is better than assuming the individual is typical of the population as a whole. Based on Bayes law, you need to consider the prevalence of a disease in a population. Also, account for the error rate of an infectious disease test. This helps evaluate the meaning of a positive test result correctly and avoid the base-rate fallacy.
Bayesian statistics (/ˈbeɪziən/BAY-zee-ən or /ˈbeɪʒən/BAY-zhən)[1] is a theory in the field of statistics based on the Bayesian interpretation of probability, where probability expresses a degree of belief in an event. The degree of belief may be based on prior knowledge about the event, such as the results of previous experiments, or on personal beliefs about the event. This differs from a number of other interpretations of probability, such as the frequentist interpretation, which views probability as the limit of the relative frequency of an event after many trials.[2] More concretely, analysis in Bayesian methods codifies prior knowledge in the form of a prior distribution.
Automatic identification and data capture (AIDC) refers to the methods of automatically identifying objects, collecting data about them, and entering that data directly into computer systems (i.e. without human involvement). Technologies typically considered as part of AIDC include bar codes, Radio Frequency Identification (RFID), biometrics, magnetic stripes, Optical Character Recognition (OCR), smart cards, and voice recognition. AIDC is also commonly referred to as “Automatic Identification,” “Auto-ID,” and “Automatic Data Capture.” http://en.wikipedia.org/wiki/Automatic_identification_and_data_capture
Adaptive control is the control method used by a controller which must adapt to a controlled system with parameters which vary, or are initially uncertain. For example, as an aircraft flies, its mass will slowly decrease as a result of fuel consumption; a control law is needed that adapts itself to such changing conditions.
The challenges facing information today are closely related to the complexity of data management, technology and social factors. Here are some of the biggest challenges: